
PyTorch is an influential deep-learning framework that enables developers to build computational graphs on the fly, making it faster to develop and iterate deep-learning models.
Intel’s PyTorch Contributions at a Glance
Intel, actively involved in the PyTorch community, ranks among the top contributors and provides numerous optimizations that enhance performance on Intel architecture. Intel started contributing to PyTorch from the early phase of the project and has upstreamed numerous CPU optimizations including making The Intel® oneAPI Deep Neural Network Library (oneDNN) default on to accelerate compute on CPUs.
Recently, we’re pushing forward CPU optimizations for TorchInductor, the new compiler backend that compiles the FX Graphs generated by TorchDynamo into optimized C++/Triton kernels.
The PyTorch team has been working on TorchDynamo (which aims to solve the graph capture problem) to make it even faster. Because Torchdynamo functions as a compiler, it must be paired with a backend compiler. This is where Intel's contribution to TorchInductor becomes essential to support multiple backend devices. Specifically, Intel optimizes TorchInductor C++/OpenMP backend, enabling users to take advantage of modern CPU architectures and parallel processing to accelerate computations.
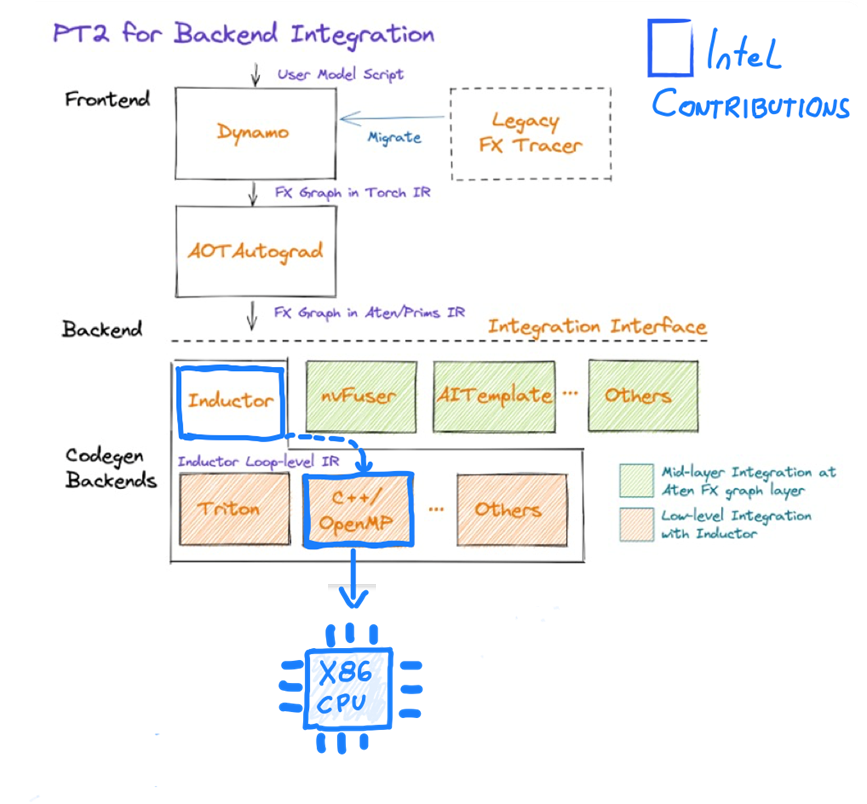
For a closer look at Intel contributions, you’ll find more details in this post or this post.
In addition to TorchInductor C++/OpenMP, Intel has contributed three other features including GNN, unified quantization backend for x86 CPUs and OneDNN Graph fusion API, you can find more details in this blog post.
Although the goal is to upstream all contributions, Intel has already introduced some bold optimizations and new hardware support in the Intel® Extension for PyTorch. Early adopters in the community can already implement this extension over PyTorch's standard version, aka Stock Pytorch.
Meet the Maintainers
Maintainers for CPU Performance
Mingfei Ma, (mingfeima on GitHub), Deep Learning Software Engineer at Intel.
Jiong Gong (Jgong5), Software Engineer at Intel.
Xiaobing Zhang (XiaobingSuper) Machine Learning Engineer at Intel.
Compiler Front-End Maintainer
Jiong Gong
Jianhui Li (Jianhui-Li), Senior Principal AI Engineer at Intel, now emeritus, was recognized by the community for his past contributions.
Find a complete list of new core and module maintainers at PyTorch.
Why Intel Contributes to Pytorch
PyTorch holds a pivotal place in any AI toolkit, allowing for smooth and swift AI application development, boosted by Intel's own contributions to the project. Intel's dedication to AI research is evident in its collaboration with PyTorch, where it has invested heavily in the platform since its debut in 2018. This unwavering commitment was spurred by Intel's pledge to arm devs with top-grade tools and technologies, facilitating high levels of performance, hardware acceleration, and cementing their collaboration in the dynamic realm of AI innovation.
Intel contributions are important for several reasons:
Collaboration
Intel actively participates in the PyTorch community to foster collaboration among devs, researchers, and industry experts. This collaborative environment encourages the sharing of ideas, promotes the development of new features and optimizations, and drives innovation forward.
Compatibility
Intel’s contributions ensure compatibility and interoperability across various hardware architectures, allowing developers to seamlessly utilize Intel's hardware capabilities such as parallelism and hardware accelerations.
Performance optimization
The superior performance provided by Intel results in faster model training and inference, contributing to overall productivity and making deep learning more accessible and impactful across a wider range of applications and use cases.
Accessibility and adoption
Through collaboration with the PyTorch community, Intel helps increase accessibility and adoption of the framework. Intel's contributions of developer tools, libraries, and educational resources empower developers to effectively leverage PyTorch on Intel architectures, promoting a diverse and inclusive ecosystem and facilitating knowledge sharing.
Sustainability
Intel's support for open source projects and open standards creates a level playing field for multiple vendors and contributors to thrive, fostering innovation and preventing vendor lock-in. This benefits developers, users, and the industry as a whole.
How to Get Involved
- Get started by installing Pytorch locally.
- Join the PyTorch community.
- Check out the GitHub page for Intel® Extension for PyTorch* for tutorials and the latest release.
About the Authors
Ezequiel Lanza is an open source evangelist on Intel’s Open Ecosystem Team, passionate about helping people discover the exciting world of AI. He’s also a frequent AI conference presenter and creator of use cases, tutorials, and guides to help developers adopt open source AI tools like TensorFlow* and Hugging Face*. Find him on Twitter at @eze_lanza
Fan Zhao is an Engineering Director of Deep Learning frameworks and libraries in AI & Analytics (AIA) at Intel. She has over 17 years of experience in open source projects and currently leads Intel CPU and GPU enabling and optimizations in deep learning frameworks and open source deep learning compilers.