What is computer vision?
Artificial intelligence (AI) is the science and technology behind enabling machines to process information. As a field of computer science, AI technologies range from analyzing vast amounts of data from customer transactions to developing business insights, understanding patterns from images or texts without much input, and predicting outcomes in previously unseen circumstances.
Computer vision is a subset of the broader field of AI that focuses on enabling machines to interpret and understand visual information from the world around us. It empowers computers to perceive, process, and analyze images and videos, opening up a wide range of possibilities across various industries – from automated defect detection in a production line to helping agronomists identify plant diseases and develop targeted pesticide applications to clinicians diagnosing diseases from X-ray images with the help of computer vision.
While computer vision technology is extremely promising and has received wide adoption across industries, we recognize the challenges for organizations to embark on this journey to build innovative solutions with computer vision. We have discussed these opportunities and challenges in our previous blogs.
Among the fundamental reasons we built the Intel Geti platform were to break these bottlenecks and bring the right people on your teams together to work with the right datasets, through an active learning cycle, and effectively collaborate to build computer vision models and help you innovate with AI.
In this blog, we will delve deeper into different computer vision tasks and discuss how Intel Geti software helps users speed up their model development workflows.
Nomenclature: Computer vision vs. machine vision
Often, the terms “computer vision” and “machine vision” are used interchangeably, but they refer to different aspects of visual processing.
Computer vision is a broader term that encompasses the entire range of techniques and technologies aimed at enabling machines to interpret visual data. It focuses on higher-level tasks, such as object recognition, scene understanding, and image analysis.
On the other hand, machine vision is a subset of computer vision that deals specifically with automated visual inspection and analysis for industrial applications. Machine vision is more narrowly focused on tasks like quality control, product inspection, and process optimization in manufacturing and production environments.
Types of computer vision tasks
Computer vision tasks can be broadly categorized into several types, each serving a unique purpose. Broadly, there are three sub-categories based on how much supervision is provided about the data and the regions of interest in the data:
Supervised Learning
Supervised learning is a type of machine learning where the model is trained on labeled data, meaning each input sample is associated with a corresponding target label. In the context of computer vision, supervised learning tasks include:
Image Classification: Image classification is the task of assigning a label or category to an entire input image. For example, classifying images of animals into different species or identifying objects in a photograph. There can be multiple categories of image classification, where an image may be assigned just a single label or class, or in another situation, an image may be associated with multiple types of objects, and thus, assigned multiple labels or classes. Such a computer vision model learns from the characteristics of the labeled data and helps identify the specific classes it was trained for.
When to Use:To say it simply, image classification is suitable when you want to determine what is in an image, but you don’t need to know the precise location of objects. It is commonly used in applications like content-based image retrieval, sentiment analysis from images, and identifying diseases from medical images.
Object Detection: Object detection is the task of locating and classifying multiple objects within an image – i.e., identifying where the object is in the image. It goes beyond image classification by not only identifying objects but also drawing bounding boxes around them.
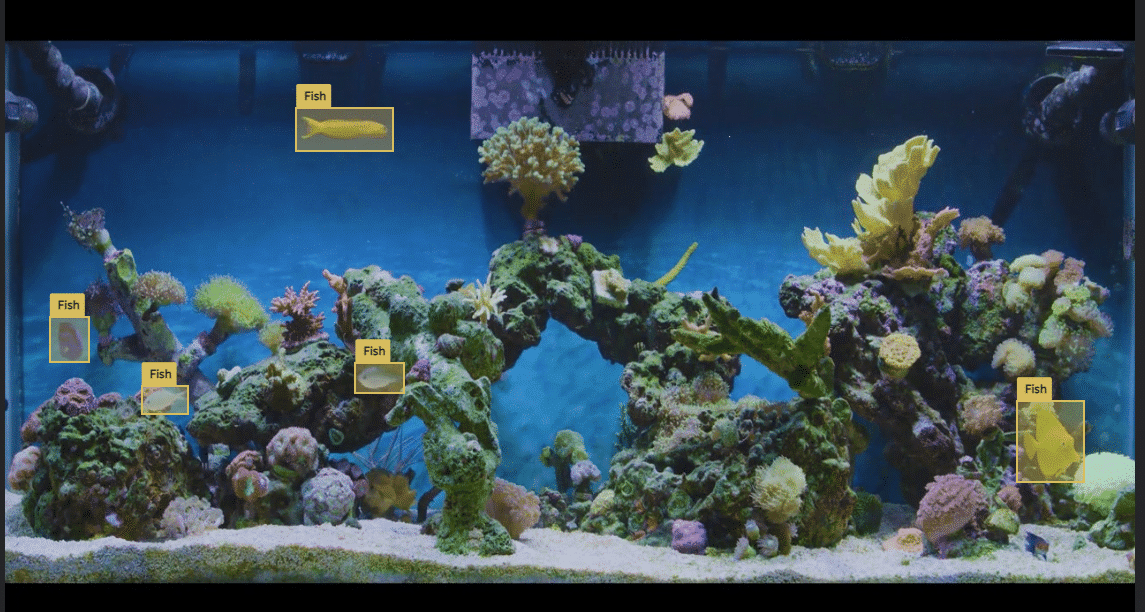
Figure 1: Object detection example for detecting fish in the aquarium with bounding boxes.
When to Use: Object detection is appropriate when you want to detect and locate multiple instances of objects in an image. It is widely used in applications like pedestrian detection, face recognition, and autonomous driving.
Image Segmentation: Image segmentation goes a step further from the object detection type of tasks and helps identify segments of interest in an image by its shape – i.e., how it is shaped. This task is often used for object localization and focuses on identifying the exact shape of the objects or regions of interest, allowing for in-depth image analysis.
There are often two categories of image segmentation, namely semantic segmentation, and instance segmentation. A semantic segmentation task does not distinguish between objects of the same category, but an instance segmentation task does and thus is more suited for object counting tasks as well.
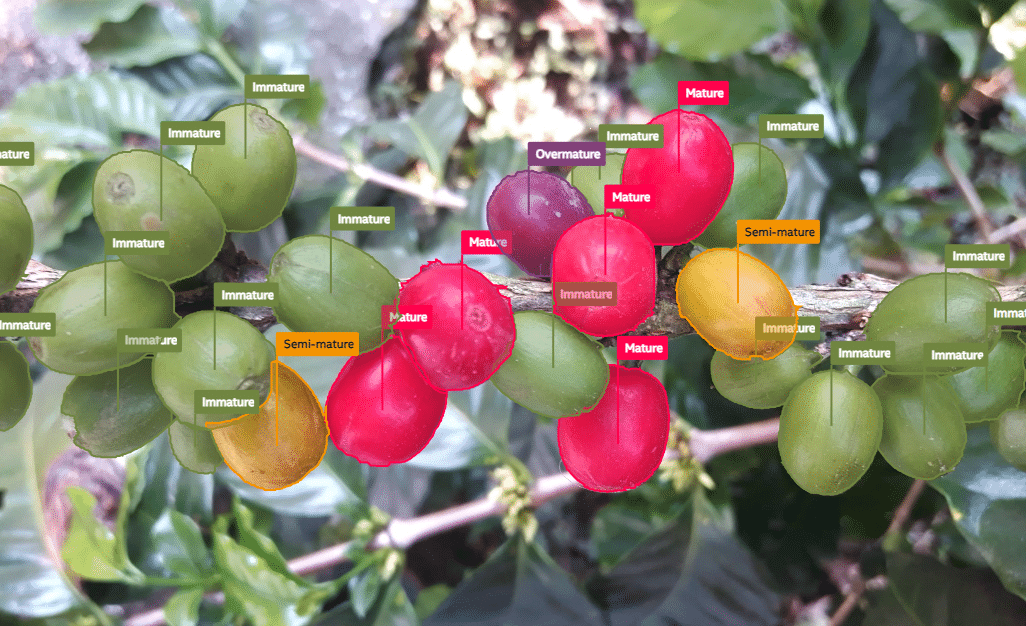
Figure 2: Instance Segmentation examples for coffee fruits.
When to Use: Image segmentation is useful when you need to identify and precisely delineate the boundaries of objects in an image. It is commonly used in applications like medical image analysis – such as identifying shapes and size of tumors, autonomous vehicles, and instance segmentation in industrial defect detection – such as for counting objects.
Supervised learning tasks are helpful when we know what we are trying to identify, and we have enough data to train a deep neural network model on identifying those objects. However, often we have scenarios where we may not even know what the type of objects or situation we are trying to identify may look like. Consider a production line example, developing a new product – it is not clear what the defects may look like, and a camera monitoring the product line may mainly be seeing images of normal products. A semi-supervised learning task can be very helpful to address such scenarios.
Semi-Supervised Learning
Semi-supervised learning is a hybrid approach that combines both labeled and unlabeled data during model training. It can be especially useful when obtaining large amounts of labeled data is challenging.
Anomaly Detection: Anomaly detection can be an example of semi-supervised learning, where a neural network model is trained to understand what normal data looks like – i.e., only normal data is supplied for model training. And, when the model sees anomalous data, that deviates from the patterns it has learned from the normal data, it identifies the anomalies. It is commonly used for defect detection in manufacturing or identifying anomalies in medical images.
When to Use: Anomaly detection is ideal when you need to identify rare occurrences or deviations from the norm in visual data. It can be applied in quality control, surveillance, and medical diagnosis.
Unsupervised Learning
Unsupervised learning involves training a model on unlabeled data without explicit target labels. The model must find patterns and structure within the data on its own. More generalizable, large-scale models are typically trained to solve such unsupervised problems of pattern recognition.
Task types supported in Intel® GetiTM software
Intel Geti software provides an intuitive user interface enabling users to easily get started with building their computer vision models. The easy templates in Intel Geti software enable customers to just pick the task type, add labels for the objects they are trying to train deep learning model for and get started. Powered with intelligent algorithms like active learning, it further boosts model development workflow for AI teams, and with built-in optimizations for the OpenVINOTM toolkit, enables an easy path to scalably deploying models in the production environment.
Object Detection task
Traditional object detection use-cases involve axis-aligned bounding boxes to identify the objects or regions of interest, as shown earlier in Figure 1. Intel Geti software provides an intuitive way to not only build and train axis-aligned object detection models but also, enables users to train deep neural network models with rotated bounding boxes. Rotated bounding boxes become highly useful when the objects you are looking for are not axis-aligned and may appear close to each other causing a large overlap in the case of regular, axis-aligned, bounding boxes.

Figure 3: Axis-aligned object detection vs. rotated object detection to identify transistors. As seen from the image above, overlapping bounding boxes can be easily reduced with rotated object detection for such scenarios.
Image Classification task
Intel Geti software allows users to build multiple types of classification projects, based on their use cases – single-label classification, multiple-label classification, and hierarchical classification. A single-label classification task allows users to train a binary or multi-class classification model that can learn about identifying the presence of one object type (or class) in each image. The model may be trained to identify many different objects (at least two for a binary classification task), but it can associate each image with only one object or class. A multi-label classification, on the other hand, can associate each image with more than one object or class. A hierarchical classification task can learn about parent-child relationships for different types of classes that may be present. These classification tasks also allow users to analyze saliency maps and heat maps, thereby being able to understand and explain what the model is learning from.

Figure 4. Single label assigned to an entire image (left) vs. Multiple labels assigned to the image (right).
Image Segmentation task
Both semantic segmentation and instance segmentation tasks are supported in Intel Geti software. You may have multiple objects belonging to the same class in a given image. As described earlier, a semantic segmentation task will group objects belonging to the same entity or class, while an instance segmentation task allows you to identify them as individual objects, as separate entities, and enable you to count them. For example, if you have an image with multiple people, a semantic segmentation will group them and recognize them collectively as people, without differentiating the individuals. On the other hand, an instance segmentation-type task will enable identifying every individual in the given image.
Because labeling for shapes can be complex, Intel Geti software provides several smart annotation helpers. A simple polygon drawing feature helps delineate shape boundaries using free-hand drawing, while an interactive segmentation feature enables quick delineation by just dropping a dot in the positive or negative region of a specific object – in other words, it works like a magic wand.

Figure 5. Image segmentation tasks supported in Intel Geti software – instance segmentation and semantic segmentation. Instance segmentation helps uniquely identify instances of objects, but semantic segmentation clubs nearby instances of the objects together.
Anomaly-based tasks
Intel Geti software supports three types of semi-supervised learning tasks. All of these are anomaly-based tasks and can be categorized as anomaly classification, anomaly detection, and anomaly segmentation. The main idea behind these tasks is that the model only learns from the data provided as normal data and tries to make predictions on the anomalous data. As described in the previous section, such semi-supervised learning methods are extremely useful when obtaining large amounts of anomalous data or data with defects is very difficult. Defect detection use cases or healthcare use cases are common examples where such tasks prove extremely helpful. In Intel Geti software, the same dataset can be used to build either anomaly classification – where the model only classifies whether an input image is anomalous or normal, anomaly detection – where the model uses the information and localizes the anomaly, and anomaly segmentation – where the model delineates the shape of the anomaly.

Figure 6. Anomaly classification assigning label to entire image (left), vs. Anomaly detection that also localizes anomaly (smoke in the right image) with a bounding box.
Task-chains
Additionally, Intel Geti software provides the ability to build chained tasks – where it may not be possible to train a single neural network model to solve the problem easily. Breaking tasks in this way also enables a better collaboration experience. For example, a radiologist may be able to identify a tumor from the CT scan images, but classifying those tumors to be benign or malignant will need inputs from a cancer specialist (or oncologist). In such a situation, it will be prudent to build a first-level model to localize the tumor and a more dedicated model to classify the specific localized tumor.
This is often the case in many real-world use cases where a combination of multiple computer vision models is used to solve a complex problem, and output from a model is fed as an input into the subsequent neural network. There may be additional pre- and post-processing steps needed in such scenarios. Intel Geti software provides two types of task-chain templates – a detection and classification task chain, and a detection and segmentation task chain. The platform also takes care of all the pre-and post-processing steps in between these tasks, making it easier for users to solve their complex problems.
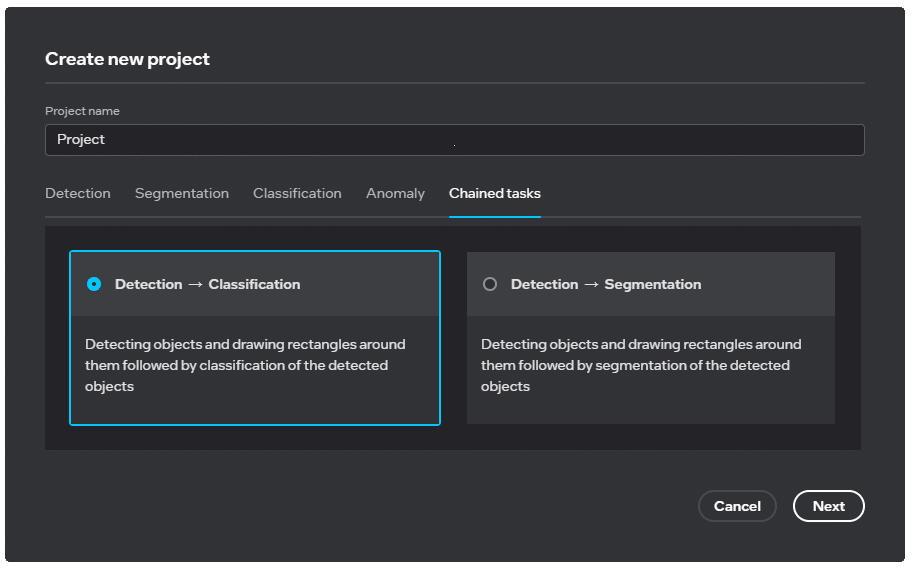
Figure 7: Task chain templates in Intel Geti software
What problems are you solving with computer vision?
Computer vision is a dynamic and exciting field of artificial intelligence that has the potential to revolutionize how we interact with technology and the world around us. Many of our customers have seen the value Intel Geti software is providing in speeding up their computer vision workflows, as discussed in the case studies.
As computer vision continues to advance, we can expect even more exciting applications and innovations that will shape various industries and improve our daily lives. We are looking forward to working with many of our new and existing customers on this journey! What problems are you solving with computer vision today? Reach out to us to learn more about how Intel Geti software can help you speed up time to value for your investments.