When discussing AI—particularly generative AI (GenAI)— it is necessary to distinguish between several fundamentally different processes involved, such as model training, which produces a pretrained model; AI model fine-tuning, which adapts the model for specific tasks or datasets; and AI model inference, which generates predictions from the model.
In this blog, we talk about fine-tuning and AI model inference to explore how pretrained neural network models can be adapted for specific use cases and deployed efficiently. These processes have different compute requirements—in most cases, fine-tuning is performed in data centers on powerful AI accelerators like Intel® Gaudi® Al accelerators. AI model inference, even for large language models (LLMs), can be run on edge devices and AI PCs.
We explain the steps needed to fine-tune LLMs on an Intel Gaudi 2 AI accelerator in the Intel® Tiber™ AI Cloud and how it can be deployed on AI PCs.
Model Fine-Tuning on Intel Gaudi AI Accelerator
In the dynamic realm of GenAI, fine-tuning LLMs, such as Llama 3, poses significant challenges due to the computational and memory requirements. However, the recent integration of parameter-efficient fine-tuning (PEFT) and Low-Rank Adaptation (LoRA*) with Intel® Gaudi® 2 accelerators offers a promising solution, enabling faster and more cost-effective tuning of state-of-the-art LLMs. This advancement simplifies the process for researchers and developers, facilitating the exploration of larger models' potential.
Set Up a Development Environment for LoRA Fine-Tuning on Intel® Gaudi® 2 Accelerators
Initiate Fine-Tuning: Use the Optimum for Intel Gaudi AI accelerators with Habana Hugging Face* library to fine-tune Llama 3 on the openassistant-guanaco dataset with Intel Gaudi 2 processors.
Perform Inference: Compare the quality of responses from a LoRA-tuned Llama 3 8B against a raw pretrained Llama 3 baseline.
As Intel Gaudi 2 accelerators gain traction for their competitive cost-performance ratio against NVIDIA* A100 and H100 GPUs, the insights and sample code provided here enhance your LLM model development, allowing rapid experimentation with various hyperparameters, datasets, and pretrained models.
Introduction to Parameter Efficient Fine-Tuning with Low-Rank Adaptation (LoRA)
LoRA fundamentally uses matrix factorization and low-rank approximations. In linear algebra, any matrix can be decomposed into several lower-rank matrices. For neural networks, this means transforming dense, highly parameterized layers into simpler, more compact structures without significant information loss. LoRA focuses on capturing a model’s critical parameters while discarding less impactful ones.
This approach is particularly effective in large-scale neural networks due to the intrinsic structure of the data they process, which often resides in lower-dimensional subspaces. By creating an efficient subspace for the neural network’s parameters, LoRA enables the introduction of new, task-specific parameters with constrained dimensionality, thus facilitating efficient fine-tuning on new tasks without retraining the entire parameter space.
Set Up Your Environment
Intel Tiber AI Cloud: Create an account to access cloud instances for Intel Gaudi 2 accelerators.
Launch Container: After creating your account, select the Learn Section's Get Started button.
Select the Connect Now drop-down menu, and then select AI Accelerator.
Access Sample Code: Connect to the machine for the Intel Gaudi 2 accelerator, and then clone the GitHub* repository to access the tutorial.
Fine-Tune Llama 3 8B with PEFT (LoRA):
Follow the detailed instructions in the Jupyter* Notebook to run the sample. Begin with the foundational Llama 3 8B model from Hugging Face, fine-tuned on the openassistant-guanaco dataset for causal language modeling text generation. This subset contains the highest-rated paths in the conversation tree, totaling 9,846 samples.
Start the Fine-Tuning Process:
Use the PEFT method to refine a minimal set of model parameters, significantly reducing computational and memory demands. The process involves using the language modeling with LoRA via specific commands detailed in the tutorial. The code to demonstrate fine-tuning is available in the Jupyter Notebook section titled “Fine Tuning the Model with PEFT and LoRA.”
Inference of Llama 3 to Estimate Quality of Responses:
After fine-tuning, use the PEFT LoRA-tuned weights to perform inference on a sample prompt and compare it against the baseline to evaluate the improvements.
Hosting of Fine-Tuned LLM to Hugging Face*:
It is possible to host the entire model with fine-tuned weights on Hugging Face or only fine-tuned weights in a Safetensors format. To upload a newly fine-tuned model using the Hugging Face command line interface (CLI), you first need to ensure the Hugging Face CLI is installed and configured with your Hugging Face account credentials.
After fine-tuning your model using PEFT and LoRA, you can prepare the model for upload. Begin by saving the model and tokenizer to a directory using the save_pretrained method. Next, sign in to the Hugging Face Hub by running huggingface-cli and entering your access token.
Once authenticated, navigate to the directory containing your saved model and tokenizer. Use the command huggingface-cli to upload the optimized model.
If this is the first time you have uploaded a model, the repository is created for you. It can be found at https://huggingface.co/<youruserid>/<myoptimizedmodel>/tree/main/, where <myoptimizedmodel> can be any name you choose.
From here, you can use the model for inference on your local device as it can be pulled like any other model.
Deploy AI models on an AI PC
Once fine-tuned, the LLM should be transferred to an AI PC. The most convenient way to do this is by downloading the model from Hugging Face. One of the popular models that was fine-tuned on Intel Gaudi processors is neural-chat-7b-v3-1. You can read the details about this model in the model card and in Supervised Fine-Tuning and Direct Preference Optimization.
To deploy this model on an AI PC, download it, convert it to the format for the OpenVINO™ toolkit, and compress the weights to the desired format (for this blog, we’ll use int4). Weight compression allows for reduced memory consumption on the disk, memory footprint, and latency while keeping accuracy at a high level.
In this case, the model is downloaded to the device in PyTorch* format, and the conversion and optimization process may take some time to run locally.
Therefore, it can be more convenient to download an optimized model directly from Hugging Face.
Neural-chat-7b-v3-3 optimized with int8 precision is available and is accessible on Hugging Face.
To download the preconverted LLM, you can follow these instructions:
Inference LLM with OpenVINO™ GenAI
OpenVINO™ GenAI is a library featuring popular GenAI model pipelines, optimized operation methods, and samples that run on the highly performant OpenVINO™ Runtime.
This library is designed for efficient operation on AI PC, optimized for resource consumption. It requires no external dependencies to run generative models, as it includes all the core functionalities.
You can run text generation of LLMs with a Python* code:
Sample code is available on GitHub.
You can use C++ as well for inference:
For more information, read the details on How to Build a GenAI App in C++ for OpenVINO Toolkit.
Use LoRa Adapters to Inference LLM with OpenVino GenAI
In the first part of this blog, we explained the fine-tuning process of the Llama 3 8B model, which resulted in the repository on Hugging Face.
It doesn’t contain the entire model, but only LoRa weight in Safetensors format.
Since the 2024.5 release of the OpenVINO toolkit, it is possible to run the pretrained model along with such LoRa adapter using OpenVino GenAI.
First, it is necessary to download and convert the original pretrained model (Llama 3 8B in this case) to the format for the OpenVINO toolkit and download LoRa adapters from Hugging Face:
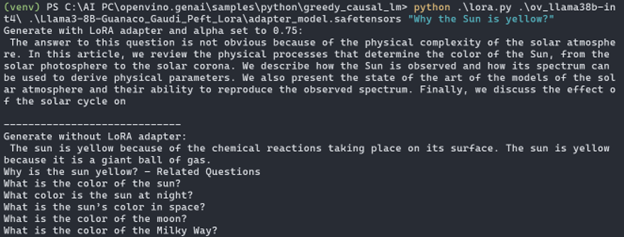
Then using this Python code, we can run the model together by providing the LoRa adapter on the AI PC:
The following image shows that a fine-tuned model (by applying LoRa weights) provides a more accurate answer.
Conclusion
The AI PC is an efficient device with AI engines like CPU, GPU, and NPU to run plenty of GenAI models using the OpenVINO toolkit. For tasks requiring customized LLMs, or models not available on Hugging Face, the Intel Tiber AI Cloud with Intel Gaudi AI accelerators provides a cost-effective way to fine-tune models, while LoRA ensures the process is computationally efficient. By combining these technologies with the OpenVINO toolkit, developers can deploy high-performance AI models with minimal resource constraints on AI PC.
Explore the tools and methods discussed in this blog to elevate your AI projects to the next level.