Summary
SqueezeLLM is a novel quantization method developed by University of California (UC) Berkeley researchers to enable efficient and accurate generative LLM inference. However, it requires custom kernel implementations and, therefore, additional implementation effort to provide cross-platform support. By taking advantage of CUDA*-to-SYCL* migration using the SYCLomatic tool from the Intel® oneAPI Base Toolkit, we quickly attained a 2.0x speedup on Intel® Data Center GPUs with 4-bit quantization without any manual tuning. This allows for cross-platform support with minimal additional engineering work required for porting the kernel implementations to different hardware back ends.
SqueezeLLM: Accurate and Efficient Low-Precision Quantization to Enable Efficient LLM Inference
LLM inference is becoming a predominant workload as it enables a wide range of applications. However, LLM inference is extremely resource intensive, requiring high-end computers for serving. Additionally, while prior machine learning workloads have been primarily compute-bound, generative LLM inference is predominantly memory-bandwidth bound, as it suffers from low data reuse since output tokens must be generated sequentially. One solution to reduce memory consumption and latency is low-precision quantization, but quantizing LLMs to low precision (for example, less than 4 bits) without unacceptable accuracy loss is challenging.
Researchers at UC Berkeley have developed SqueezeLLM as a solution to enable efficient and accurate low-precision quantization. SqueezeLLM incorporates two crucial innovations to address challenges with prior methods. It uses sensitivity-weighted non-uniform quantization, which addresses the inefficient representation of the underlying parameter distribution due to the constraints of uniform quantization by using sensitivity to determine the best allocation for quantization codebook values, thereby preserving model accuracy. Additionally, SqueezeLLM introduces dense-and-sparse quantization, where very large outliers in LLM parameters are addressed by keeping outlier values in a compact sparse format, which enables quantization of the remaining parameters to low precision.
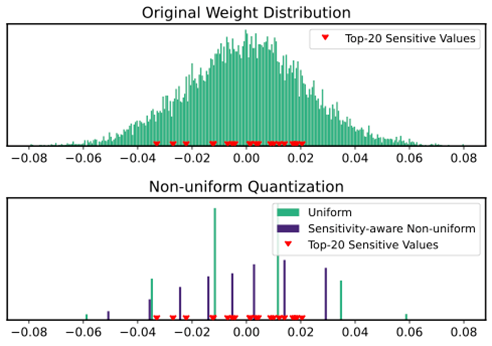
Figure 1. SqueezeLLM employs non-uniform quantization to represent the LLM weights in reduced precision optimally. The non-uniform quantization scheme accounts for the sensitivity of parameters to error and not just the magnitude of values when deriving the non-uniform codebooks, thereby providing high accuracy for low-precision quantization.
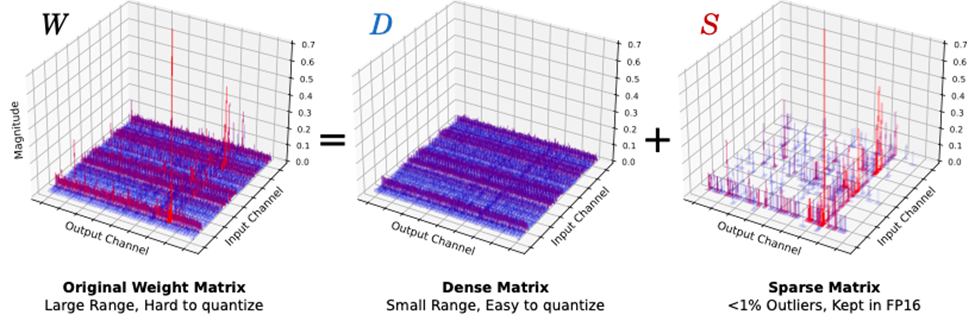
Figure 2. SqueezeLLM uses dense-and-sparse quantization, where a small percentage of outlier values are stored separately in higher precision. This reduces the required range that needs to be represented by the remaining dense component, thereby facilitating accurate low-precision quantization for the dense matrix.
Challenge: Providing Cross-Platform Support for Low-Precision LLM Quantization
The approach in SqueezeLLM facilitates efficient and accurate low-precision LLM quantization to reduce memory consumption during LLM inference, and also allows for significant latency reduction relative to baseline FP16 inference. Our aim was to provide cross-platform support in order to enable widespread availability of these techniques for optimizing LLM inference on platforms such as Intel Data Center GPUs. However, SqueezeLLM relies on manual custom kernel implementations to use non-uniform quantization to provide accurate representation with very few bits per parameter and to use dense-and-sparse quantization to address the outlier issue with LLM inference. Although these kernel implementations are relatively straightforward, porting and optimizing them manually for different target hardware architectures is still undesirable. We initially designed the SqueezeLLM kernels using CUDA, and given that it took weeks to implement, profile, and optimize these kernels, we anticipated a significant overhead when porting our kernels to run on Intel Data Center GPUs.
We, therefore, wanted a solution to be able to quickly and easily port our custom CUDA kernels to SYCL in order to target Intel Data Center GPUs. This requires both being able to convert the kernels with minimal manual effort and more easily adapting the Python*-level code to call the custom kernels to avoid disrupting the rest of the inference flow. Additionally, we wanted the ported kernels to be performant so that Intel customers can fully enjoy the efficiency benefits of SqueezeLLM.
Fortunately, SYCLomatic provides a solution to allow for cross-platform support without adding additional engineering effort. Using the CUDA-to-SYCL code migration with SYCLomatic, the efficient kernel methods can be decoupled from the target deployment platform, thereby enabling inference on different target architectures with minimal additional engineering effort. As demonstrated with our performance analysis, the kernels ported using SYCLomatic provide efficiency benefits immediately without any manual tuning, achieving 2.0x speedup on Intel Data Center GPUs when running the Llama 7B model.
Solution: A CUDA-to-SYCL Migration That Uses SYCLomatic to Enable Deploying Quantized LLMs on Different Platforms
Initial Conversion
A development environment containing the Intel® oneAPI Base Toolkit was used to run SYCLomatic conversion. The kernel was migrated to SYCL using the SYCLomatic conversion command, dpct quant_cuda_kernel.cu. We are pleased to report that the conversion script automatically generated correct kernel definitions and modified the kernel implementations wherever necessary. The following examples show how the kernel implementation and invocations were modified to SYCL-compatible code without manual intervention.
Example: Kernel Definition
VecQuant4MatMulKernelNUQPerChannel(
const float* __restrict__ vec,
const int* __restrict__ mat,
float* __restrict__ mul,
const float* __restrict__ lookup_table,
int height,
int width)
{
int row = BLOCKHEIGHT4 * blockIdx.x;
int col = BLOCKWIDTH * blockIdx.y + threadIdx.x;
__shared__ float blockvec[BLOCKWIDTH];
blockvec[threadIdx.x] = vec[(row / BLOCKHEIGHT4) * BLOCKWIDTH + threadIdx.x];
...
}
Example: Kernel Invocation
... dim3 blocks(
(height + BLOCKHEIGHT4 - 1) / BLOCKHEIGHT4,
(width + BLOCKWIDTH - 1) / BLOCKWIDTH
);
dim3 threads(BLOCKWIDTH);
VecQuant4MatMulKernelNUQPerChannel<<<blocks, threads>>>(
vec.data_ptr<float>(),
mat.data_ptr<int>(),
mul.data_ptr<float>(),
lookup_table.data_ptr<float>(),
height, width
); ...
Example: Migrated Kernel Definition
void VecQuant4MatMulKernelNUQPerChannel( const float* __restrict__ vec, const int* __restrict__ mat,
float* __restrict__ mul,
const float* __restrict__ lookup_table,
int height,
int width,
const sycl::nd_item<3> &item_ct1,
float *blockvec,
sycl::local_accessor<float, 2> deq2)
{
int row = BLOCKHEIGHT4 * item_ct1.get_group(2);
int col = BLOCKWIDTH * item_ct1.get_group(1) + item_ct1.get_local_id(2);
blockvec[item_ct1.get_local_id(2)] = vec[(row / BLOCKHEIGHT4) * BLOCKWIDTH + item_ct1.get_local_id(2)];
...
}
Example: Migrated Kernel Invocation
... sycl::range<3> blocks4(1, (width4 + BLOCKWIDTH - 1) / BLOCKWIDTH,
(height4 + BLOCKHEIGHT4 - 1) / BLOCKHEIGHT4);
sycl::range<3> threads4(1, 1, BLOCKWIDTH);
q_ct1.submit([&](sycl::handler &cgh) {
sycl::local_accessor<float, 1> blockvec_acc_ct1(
sycl::range<1>(128 /*BLOCKWIDTH*/), cgh
);
sycl::local_accessor<float, 2> deq2_acc_ct1(
sycl::range<2>(16, 128 /*BLOCKWIDTH*/), cgh
);
auto vec_data_ptr_float_ct0 = vec.data_ptr<float>();
auto mat4_data_ptr_int_ct1 = mat4.data_ptr<int>();
auto mul_data_ptr_float_ct2 = mul.data_ptr<float>();
auto lookup_table_data_ptr_float_ct3 = lookup_table.data_ptr<float>(); cgh.parallel_for( sycl::nd_range<3>(blocks * threads, threads),
[=](sycl::nd_item<3> item_ct1) { VecQuant4MatMulKernelNUQPerChannel(
vec_data_ptr_float_ct0,
mat_data_ptr_int_ct1,
mul_data_ptr_float_ct2,
lookup_table_data_ptr_float_ct3,
height,
width,
item_ct1,
blockvec_acc_ct1.get_pointer(),
deq2_acc_ct1
);
}
); }); ...
Without any manual effort, the baseline converted kernels were ready to go.
Convert Python* Bindings to Enable Calling Custom Kernels
To call the kernel from the Python code, the bindings were adapted to use the PyTorch* XPU CPP extension (DPCPPExtension), which allowed the migrated kernels to be installed into the deployment environment by using a setup.py script:
Original CUDA Kernel Installation in the Setup Script to Install Bindings
setup( name="quant_cuda",
ext_modules=[
cpp_extension.CUDAExtension(
"quant_cuda",
["quant_cuda.cpp", "quant_cuda_kernel.cu"]
)
],
cmdclass={"build_ext": cpp_extension.BuildExtension},
)
Migrated Kernel Installation in the Setup Script to Install Bindings
setup(
name='quant_sycl',
ext_modules=[
DPCPPExtension(
'quant_sycl',
['quant_cuda.cpp', 'quant_cuda_kernel.dp.cpp',]
)
],
cmdclass={
'build_ext': DpcppBuildExtension
}
)
After installing the kernel bindings, the converted SYCL kernels could be called from PyTorch code, thereby enabling running end-to-end inference using the converted kernels. This allowed the existing SqueezeLLM Python code to be adapted more easily to support the SYCL code, with only minor modifications to call the migrated kernel bindings.
Performance Analysis for Converted Kernels
The SqueezeLLM team used Intel Data Center GPUs made available through the Intel® Tiber™ Developer Cloud to test and benchmark the ported kernel implementations. As previously mentioned, the inference kernels were converted using SYCLomatic and then adjusted to allow calling the SYCL code from the SqueezeLLM Python code. The 4-bit kernels were benchmarked on Intel Data Center GPU Max Series to assess performance improvements from low-precision quantization. This assessed whether the conversion process could produce efficient inference kernels, thereby truly enabling efficient inference for different platforms.
Table 1. Average latency and speedup for matrix-vector multiplications when generating 128 tokens using the Llama 7B model. These results demonstrate that we can attain significant speedups with the ported kernels without any manual tuning.
| Kernel | Latency (in seconds) |
|---|---|
| Baseline: fp16 Matrix-Vector Multiplication | 2.584 |
| SqueezeLLM: 4-bit (0% sparsity) | 1.296 |
| Speedup | 2.0x |
The 4-bit kernels were benchmarked on the Intel Data Center GPU to assess the latency benefits of low-precision quantization that are attainable across different hardware back ends without modifications to the SYCL code. As shown in Table 1, SqueezeLLM can attain a 2.0x speedup on Intel Data Center GPUs relative to baseline FP16 inference when running the Llama 7B model without any manual tuning. Comparing this speedup with the results obtained on the NVIDIA* A100 hardware platform for 4-bit inference, which attained speedups of 1.7x relative to baseline FP16 inference, the ported kernels perform comparably with the handwritten CUDA kernels that were targeted for NVIDIA GPU platforms. These results highlight that CUDA-to-SYCL migration using SYCLomatic enables comparable speedups on different architectures without inducing any overheads in terms of additional engineering effort or manual tuning required once the kernels have been converted.
Conclusion
LLM inference is a core workload for emerging applications, and low-precision quantization is a key solution to improve inference efficiency. SqueezeLLM enables efficient and accurate generative LLM inference with low-precision quantization. However, it requires custom kernel implementations, making cross-platform deployment more challenging. Using the SYCLomatic migration tool enables the kernel implementation to be ported to different hardware architectures with minimal overhead. For example, 4-bit SqueezeLLM kernels that were migrated using SYCLomatic demonstrate 2.0x speedup on Intel Data Center GPUs without any manual tuning. SYCL conversion, therefore, allows for supporting different hardware platforms without significant engineering overhead and helps to democratize efficient LLM deployment.
More Information
Make your LLM inference pipeline more efficient with SqueezeLLM as your solution for accurate low-precision quantization:
Explore CUDA-to-SYCL conversion using SYCLomatic to enable efficient cross-platform deployment with custom kernel implementations:
Acknowledgements
The authors would like to acknowledge the SqueezeLLM team (Sehoon Kim, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, and Michael W. Mahoney) for their contributions to developing this methodology for accurate low-precision LLM quantization. The SqueezeLLM team would like to acknowledge the gracious support from the oneAPI Center of Excellence in sponsoring our work. In particular, we would like to acknowledge Anoop Madhusoodhanan, Alexandra Yu, and Xiao Zhu for help with accessing and setting up Intel Data Center GPUs in the Intel Tiber Developer Cloud and with providing technical support to aid with porting our kernel implementations using SYCLomatic in order to provide cross-hardware platform support. Additionally, we would like to acknowledge Nikita Sanjay Shiledarbaxi for providing feedback on the draft for this story. We would also like to acknowledge gracious support from Google Cloud Platform* service, Google TPU Research Cloud team, and specifically Jonathan Caton, Jing Li, Jiayu Ye, and Professor David Patterson. Professor Keutzer's lab is sponsored by Intel Corporation and the Intel vLab team, as well as other Berkeley Artificial Intelligence Research Lab (BAIR) sponsors. Our conclusions do not necessarily reflect the position or the policy of our sponsors, and no official endorsement should be inferred.